ųą═ČŠW2024-05-06 11:34 üĒį┤Ż║ųą═ČŠW
ųą═ČŅÖå¢ųž░§═Ų│÷"«aśI┤¾─X"ŽĄ┴ą«aŲĘŻ¼Ė▀ą¦┘x─▄«aśI═Č┘Y╝░«aśI░lš╣Ė„ĘN╣żū„ł÷Š░Ż¼ÜgėŁįćė├¾w“ׯĪ | ||||
|---|---|---|---|---|
| «aŲĘ | ║╦ą─╣”─▄Č©╬╗ | ĄŪĻæ╩╣ė├ | įćė├╔Ļšł | |
| «aśI═Č┘Y┤¾─X | ą┬┼d«aśI═Č┘YÖCĢ■Ą─Ė▀ą¦═┌Š“╣żŠ▀ | ĄŪĻæ > | ╔Ļšł > | |
| «aśIšą╔╠┤¾─X | ┤¾öĄō■Š½£╩šą╔╠īŻśIŲĮ┼_ | ĄŪĻæ > | ╔Ļšł > | |
| «aśI蹊┐┤¾─X | «aśI蹊┐╣żū„Ą─ę╗šŠ╩ĮĮŌøQĘĮ░Ė | ĄŪĻæ > | ╔Ļšł > | |
┬ōŽĄļŖįÆŻ║ 400 008 0586; 0755-82571568
╬óą┼Æ▀┤aŻ║ 
1.1.1 2024-2028─Ļųąć°╚╦╣żųŪ─▄┤¾─Żą═«aśIė░Ēæę“╦žĘų╬÷
ę╗Īóėą└¹ę“╦ž
Ż©ę╗Ż®š■▓▀└¹║├
2023─Ļ7į┬20╚šŻ¼ųąć°ÜŌŽ¾ŠųėĪ░lĪČ╚╦╣żųŪ─▄ÜŌŽ¾æ¬ė├╣żū„ĘĮ░ĖŻ©2023-2030─ĻŻ®ĪĘĪŻĪČ╣żū„ĘĮ░ĖĪĘ╠ß│÷Ż¼╝ė┐ņ▓╝Šųć°«a╚╦╣żųŪ─▄ÜŌŽ¾æ¬ė├╝╝ąg¾wŽĄĮ©įOŻ¼åóäėÜŌŽ¾ŅAł¾┤¾─Żą═Ą╚ą┬┼d╝╝ągčą░lŻ¼čą░l┤¾öĄō■“īäėĄ─╚╦╣żųŪ─▄ÜŌŽ¾ŅAł¾┤¾─Żą═ĪóĢ■įÆ╩ĮÜŌŽ¾ŅAł¾║═Ę■äšųŪ─▄ŠWĮjÖCŲ„╚╦ŽĄĮyŻ¼╔Ņ╚ļķ_š╣╚╦╣żųŪ─▄╦ŃĘ©Ą─ÖC└ĒĮŌßī蹊┐ĪŻ
2023─Ļ8į┬10╚šŻ¼╣żą┼▓┐║═žöš■▓┐┬ō║ŽėĪ░lĪČļŖūėą┼ŽóųŲįņśI2023-2024─ĻĘĆį÷ķLąąäėĘĮ░ĖĪĘĪŻĪČąąäėĘĮ░ĖĪĘ╣─äŅ╝ė┤¾öĄō■╗∙ĄAįO╩®║═╚╦╣żųŪ─▄╗∙ĄAįO╩®Į©įOŻ¼ØMūŃ╚╦╣żųŪ─▄Īó┤¾─Żą═æ¬ė├ąĶŪ¾ĪŻ
2023─Ļ10į┬20╚šŻ¼╣żśI║═ą┼Žó╗»▓┐ėĪ░lĪČ╚╦ą╬ÖCŲ„╚╦äōą┬░lš╣ųĖī¦ęŌęŖĪĘĪŻĪČųĖī¦ęŌęŖĪĘ╠ß│÷Ż¼ęį┤¾─Żą═Ą╚╚╦╣żųŪ─▄╝╝ąg═╗ŲŲ×ķę²ŅIŻ¼į┌ÖCŲ„╚╦ęčėą│╔╩ņ╝╝ąg╗∙ĄA╔ŽŻ¼ųž³cį┌╚╦ą╬ÖCŲ„╚╦“┤¾─X”║═“ąĪ─X”Īó“ų½¾w”ĻPµI╝╝ągĪó╝╝ągäōą┬¾wŽĄĄ╚ŅIė“╚ĪĄ├═╗ŲŲĪŻķ_░l╗∙ė┌╚╦╣żųŪ─▄┤¾─Żą═Ą─╚╦ą╬ÖCŲ„╚╦“┤¾─X”Ż¼į÷ÅŖŁhŠ│Ėąų¬Īóąą×ķ┐žųŲĪó╚╦ÖCĮ╗╗ź─▄┴”Ż¼ķ_░l┐žųŲ╚╦ą╬ÖCŲ„╚╦▀\äėĄ─“ąĪ─X”Ż¼┤ŅĮ©▀\äė┐žųŲ╦ŃĘ©ÄņŻ¼Į©┴óŠWĮj┐žųŲŽĄĮy╝▄śŗĪŻ
2023─Ļ12į┬15╚šŻ¼ć°╝ęöĄō■Šų░l▓╝ĪČ“öĄō■ę¬╦žx”╚²─ĻąąäėėŗäØŻ©2024-2026─ĻŻ®ĪĘĪŻĪČąąäėėŗäØĪĘ╠ß│÷Ż¼ęį┐ŲīWöĄō■ų¦│ų┤¾─Żą═ķ_░lŻ¼Į©įOĖ▀┘|┴┐šZ┴ŽÄņ║═╗∙ĄA┐ŲīWöĄō■╝»Ż¼ų¦│ųķ_š╣═©ė├╚╦╣żųŪ─▄┤¾─Żą═║═┤╣ų▒ŅIė“╚╦╣żųŪ─▄┤¾─Żą═ė¢ŠÜĪŻ═¼ĢrŻ¼▒▒Š®Īó╔Ž║ŻĪó╔Ņ█┌Īó░▓╗šĪó╦─┤©Ą╚╩Ī╩ąę▓Ļæ└m│÷┼_┤¾─Żą═«aśI░lš╣┤ļ╩®Ż¼╝ė╦┘┤¾─Żą═æ¬ė├┬õĄžĪŻ
Ż©Č■Ż®AI┤¾─Żą═▀M╚ļ“╚║─ŻĢr┤·”╔╠śI╗»╩’╣Ō│§¼F
Ż©╚²Ż®╚╦╣żųŪ─▄┤¾─Żą═Ž“ČÓ─ŻæB┌ģä▌▀M░l
ļm╚╗─┐Ū░Ė„ŅÉ╚╦╣żųŪ─▄┤¾─Żą═īė│÷▓╗ĖFŻ¼Ą½▓╗öÓā×╗»╔²╝ēŻ¼═ŲäėąąśI▀M▓Į╚į╩ŪĖ„┤¾╗ź┬ōŠW╣½╦ŠĄ─ų„╣źĘĮŽ“ĪŻ«öŪ░Ż¼╚╦╣żųŪ─▄┤¾─Żą═ė╔å╬─ŻæBŽ“ČÓ─ŻæB╔²╝ēęč│╔×ķąąśI¤ß³cŻ¼ČÓ╝ę╣½╦ŠČÓ─ŻæBAIū▀╝tĪŻ2023─Ļ11į┬Ż¼OpenAI░l▓╝┴╦GPT-4 Turbo▓óŪęķ_Ę┼┴╦GPTsŻ¼į┘┤╬ŅŹĖ▓ąąśIŻ¼Įęķ_AIGCæ¬ė├╔·æBą“─╗Ż¼Į©┴óĮyę╗Ą─Īó┐ńł÷Š░ĪóČÓ╚╬䚥─ČÓ─ŻæB╗∙ĄA─Żą═Ģ■│╔×ķ╚╦╣żųŪ─▄░lš╣Ą─ų„┴„┌ģä▌ų«ę╗ĪŻČÓ─ŻæB╩ŪīŹ¼F═©ė├╚╦╣żųŪ─▄Ą─▒žĮøų«┬ĘĪŻ─ŻæBöĄō■▌ö╚ļ┐╔Ä═ų·─Żą═─▄┴”║═ė├涾w“×╠ßĖ▀Ż¼į╩įSČÓ─ŻæBöĄō■▌ö│÷ę▓Ė³Ę¹║ŽšµīŹ╩└ĮńąĶę¬ĪŻį┌öĄō■Īó╦ŃĘ©╝░╦Ń┴”╔ŽĄ─ę¬Ū¾Č╝ę¬Ė▀ė┌å╬─ŻæBŻ¼▀@ę╗▓©ūį╚╗šZčį┤¾─Żą═░lš╣×ķŲõ╦¹─ŻæB╠ß╣®┴╦╝╝ągģó┐╝Ż¼╚╦╣żųŪ─▄┤¾─Żą═«aśIėą═¹╝ė╦┘░lš╣ĪŻ
Ż©╦─Ż®╚╦╣żųŪ─▄┤¾─Żą═┘x─▄┼cæ¬ė├▓╗öÓ╠ß╔²
╚╦╣żųŪ─▄┤¾─Żą═Į^▓╗æ¬įōų╗═Ż┴¶į┌¤ÆĮągļAČ╬Ż¼ę¬▓╗öÓ═Ųäė┤¾─Żą═Ą─░lš╣ūā│╔┐ŲīWĄ─┤¾─Żą═Ż¼ų╗ėąĖ·ąąśI╔ŅČ╚╚┌║Ž▓┼ėą┐╔─▄šµš²Ą─īŹ¼F┐╔│ų└m░lš╣ĪŻ
╩ūŽ╚╩ŪÅ─═©ė├┤¾─Żą═Ž“┤╣ų▒┤¾─Żą═Ą─▐Dą═Ż¼╚╦╣żųŪ─▄┤¾─Żą═╬┤üĒ░lš╣īó┌ģė┌═©ė├╗»┼cīŻė├╗»▓óąąĪŻ2023─Ļ6į┬Ż¼“vėŹįŲ╩ū┤╬š²╩Į╣½▓╝ąąśI┤¾─Żą═čą░l▀Mš╣Ż¼▓ó░l▓╝┴╦├µŽ“BČ╦┐═æ¶Ą─“vėŹįŲMaaSĘ■äšĮŌøQĘĮ░ĖĪŻ2023─Ļ7į┬Ż¼╚A×ķ░l▓╝“▓╗ū„įŖų╗ū÷╩┬”Ą─▒P╣┼┤¾─Żą═3.0Ż¼╔ŅĖ¹š■äšĪóĮ╚┌ĪóųŲįņĪó├║ĄVĪóĶF┬ĘĪóųŲ╦ÄĪóÜŌŽ¾Ą╚ąąśIĪŻ┤╦═ŌŻ¼├µŽ“┬├ė╬Ą─“öy│╠å¢Ą└”Īó├µŽ“ßt»¤Ą─░┘Č╚“ņ`ßt”┤¾─Żą═Īó├µŽ“Į╠ė²Ą─ŠWęū“ūėį╗”┤¾─Żą═Ą╚ę▓Ļæ└m░l▓╝ĪŻŲõųąŻ¼Į╚┌ąąśIĄ─æ¬ė├ł÷Š░žSĖ╗Ż¼╩ŪūŅįń▀MąąöĄūų╗»▐Dą═Ą─ÖCśŗŻ¼│╔×ķAI┤¾─Żą═┬õĄžæ¬ė├Ą─ūŅ╝čł÷Š░ų«ę╗ĪŻĮ╚┌ąąśIĘeĄĒ┴╦░³└©Į╚┌Į╗ęūöĄō■Īó┐═æ¶ą┼Žóį┌ā╚Ą─║Ż┴┐öĄō■Ż¼┴╝║├Ą─öĄō■╗∙ĄA×ķAI┤¾─Żą═Ą─┬õĄžæ¬ė├╠ß╣®Śl╝■ĪŻ─┐Ū░Ż¼╔·│╔║═øQ▓▀ā╔ŅÉĮ╚┌┤¾─Żą═Ż¼ęčį┌ŃyąąĪóūC╚»Ą╚Į╚┌ÖCśŗųąīŹ¼F┬õĄžĪŻ
Č■Īó▓╗└¹ę“╦ž
Ż©ę╗Ż®öĄō■┘|┴┐║═ś╦ūóå¢Ņ}
╚╦╣żųŪ─▄┤¾─Żą═Ą─ė¢ŠÜąĶę¬┤¾┴┐Ą─ś╦ūóöĄō■Ż¼╚╗Č°ś╦ūóöĄō■Ą─┘|┴┐║═öĄ┴┐Č╝┤µį┌ę╗Č©Ą─å¢Ņ}ĪŻėąą®öĄō■┐╔─▄┤µį┌Ų½▓Ņ║═š`ī¦Ż¼ėąą®öĄō■ät┐╔─▄ę“×ķ▒Ż├▄║═ļ[╦ĮĄ╚å¢Ņ}¤oĘ©½@Ą├ĪŻ═¼ĢrŻ¼ė╔ė┌ś╦ūóöĄō■ąĶę¬┤¾┴┐Ą─╚╦╣żģó┼cŻ¼ę▓╩╣Ą├ś╦ūó│╔▒Š▌^Ė▀ŪęļyęįīŹ¼Fūįäė╗»ĪŻ
Ż©Č■Ż®┤¾─Żą═┐╔ĮŌßīąį║═┐╔┐┐ąįå¢Ņ}
╚╦╣żųŪ─▄┤¾─Żą══∙═∙ĘŪ│ŻÅ═ļsŻ¼ļyęįĮŌßīŲõøQ▓▀║═ąą×ķĄ─įŁę“Ż¼▀@╩╣Ą├╚╦éāļyęįą┼╚╬║═╩╣ė├┤¾─Żą═ĪŻ═¼ĢrŻ¼ė╔ė┌╚╦╣żųŪ─▄┤¾─Żą═Ą─Å═ļsąį║═Š▐┴┐Ą─ģóöĄöĄ┴┐Ż¼Ųõ┐╔┐┐ąį║═ĘĆČ©ąįę▓┤µį┌ę╗Č©Ą─å¢Ņ}Ż¼ąĶę¬▀MąąĖ³╝ėć└Ė±Ą─£yįć║═“×ūCĪŻ
Ż©╚²Ż®│╔▒Š║═ėŗ╦ŃąĶŪ¾ĘĮ├µėąŠųŽ▐ąį
▀^╚ź╬Õ─ĻüĒŻ¼AIŅIė“═©│ŻęįģóöĄĄ─öĄ┴┐üĒ║Ō┴┐ę╗éĆ─Żą═Ą──▄┴”ĪŻģóöĄįĮČÓŻ¼═©│ŻęŌ╬Čų°─Żą═─▄╠Ä└ĒĖ³Å═ļsĄ─╚╬䚯¼š╣╩Š│÷Ė³ÅŖĄ──▄┴”ĪŻ└²╚ńŻ¼ūŅ┤¾─Żą═Ą─ģóöĄöĄ┴┐├┐─Ļį÷╝ė┴╦╩«▒Č╗“Ė³ČÓŻ¼├┐┤╬į÷╝ėČ╝ĦüĒ┴╦ęŌŽļ▓╗ĄĮĄ──▄┴”öUš╣Ż¼╚ńŠÄ│╠║═ĘŁūg─▄┴”ĪŻ╦∙ęį┤¾ą═╔±ĮøŠWĮj─Żą══©│Ż▒╗šJ×ķąį─▄Ė³ā×ĪŻ
╚╦╣żųŪ─▄┤¾─Żą═╩╣ė├Ą─ģóöĄöĄ┴┐śOČÓŻ©ėąĄ─│¼▀^1000ā|éĆŻ®Ż¼├┐éĆģóöĄČ╝ąĶę¬ėŗ╦Ń┘Yį┤üĒ╠Ä└ĒĪŻ▒M╣▄┤¾─Żą═Ż©╚ńGPTŽĄ┴ąŻ®į┌╝╝ąg╔ŽŅIŽ╚Ż¼Ą½▀@ą®─Żą══∙═∙ęÄ─Ż²ŗ┤¾Ūęī”ėŗ╦Ń┘Yį┤Ą─ąĶŪ¾śOĖ▀ĪŻ├┐«ö┤¾─Żą═į┌─▄┴”╔Žėą’@ų°╠ß╔²ĢrŻ¼┤¾─Żą═Ą─ė¢ŠÜ║═▀\ąą│╔▒Šę▓╝▒äĪ╔Ž╔²ĪŻ╝┤▒ŃųŪ─▄┤¾─Żą═╩Ūķ_į┤Ą─Ż¼įSČÓ蹊┐š▀║═ąĪą═Ų¾śIę▓ļyęį│ąō·Ųõ╦∙ąĶĄ─░║┘Fėŗ╦Ń│╔▒ŠĪŻ▓╗āH╚ń┤╦Ż¼įSČÓAI蹊┐š▀į┌▀@ą®─Żą═Ą─╗∙ĄA╔Ž▀MąąĄ³┤·ķ_░lŻ¼ęįäōįņ▀mė├ė┌ą┬╣żŠ▀║═«aŲĘĄ─ūį╝║Ą──Żą═Ż¼Ą½┤¾─Żą═Ą─Å═ļsąįę▓ūīŲõūāĄ├Ė³╝ė└¦ļyĪŻ
Ż©╦─Ż®ć°ā╚═Ō╚╦╣żųŪ─▄┤¾─Żą═Ą──▄┴”▓ŅŠÓ╚į╚╗┤µį┌
«öŪ░Ż¼╬ęć°┼cOpenAIĄ─▓ŅŠÓš²į┌└Ł┤¾Ż¼▓╗╩Ūį┌┐sąĪĪŻį┌SuperCLUE£yįuųąŻ¼GPT4-Turboęį┐éĘų89.79Ęų▀b▀bŅIŽ╚Ż¼Ė▀ė┌ć°ā╚╦∙ėąĄ─┤¾─Żą═╝░ć°═ŌĄ─┤·▒Ēąį┤¾─Żą═ĪŻć°ā╚Ą├ĘųūŅĖ▀Ą─┤¾─Żą═╩Ū╬─ą─ę╗čį4.0Ż¼Ą½ŠÓļxGPT4-Turbo╚įėą15.77Ą─Ęų▓ŅĪŻ
¼Fį┌ć°ā╚ų„┴„Ą─┤¾─Żą═Ą──▄┴”╦«ŲĮ╗∙▒Š╔Žį┌GPT3.5╔ŽŽ┬ĪŻ
╚╦╣żųŪ─▄┤¾─Żą═Ą─║╦ą─▒┌ēŠ░³└©╦Ń┴”ĪóöĄō■Īó╦ŃĘ©ĪŻų╗ėąśO╔┘Ą─Ų¾śI─▄ē“Å─Ņ^ĄĮ╬▓Ąž═Ļ│╔«aśI╝ēčą░lĪŻ╚ńĮ±Ż¼─Żą═ģóöĄųĖöĄ╝ēį÷ķLŻ¼ė¢ŠÜ╦∙ąĶ╦Ń┴”Š▐┤¾Ż¼Ū¦ā|╝ēäeĄ─═©ė├┤¾─Żą═Ż¼ė¢ŠÜę╗┤╬Š═ąĶę¬ĖČ│÷ÄūŪ¦╚fĄ─│╔▒ŠĪŻ«öŪ░ć°ā╚ęč░l▓╝Ą─┤¾─Żą═ųąŻ¼ģóöĄęÄ─Ż▀_ĄĮŪ¦ā|╝░ęį╔ŽĄ─ÅS╔╠āH×ķ10éĆū¾ėęĪŻ┤╦═Ōį┌├└ć°ūŅą┬ę╗▌åĄ─ĘŌµiųŲ▓├Ž┬Ż¼ć°«a╗»╠µ┤·ĘĮ░ĖĄ─ąĶŪ¾Ė³╝ėŲ╚ŪąĪŻĄ½į┌║▄ķLę╗Č╬Ģrķgā╚Ż¼ąŠŲ¼┼c╦Ń┴”╚įĢ■╩Ūć°«a╚╦╣żųŪ─▄┤¾─Żą═┼cChatGPTų«ķgę╗Ą└Š▐┤¾Ą─°Ö£ŽĪŻ
2022─ĻŻ¼╬ęć°╚╦╣żųŪ─▄«aśIęÄ─Ż▀_ĄĮ5,080ā|į¬Ż╗2023─ĻŻ¼╬ęć°╚╦╣żųŪ─▄«aśIęÄ─Ż╝s▀_ĄĮ5,452ā|į¬ĪŻ
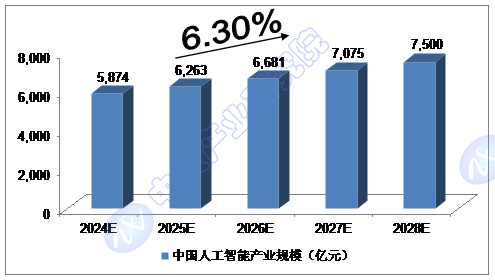
╬ęéāŅAėŗŻ¼2024─Ļ╬ęć°╚╦╣żųŪ─▄«aśIęÄ─Żīó▀_ĄĮ5,874ā|į¬Ż¼╬┤üĒ╬Õ─ĻŻ©2024-2028Ż®─ĻŠ∙Å═║Žį÷ķL┬╩╝s×ķ6.30%Ż¼2028─Ļīó▀_ĄĮ7,500ā|į¬ĪŻ
öĄō■üĒį┤Ż║ųą═Č«aśI蹊┐į║

«aśI═Č┘Y┼c«aśI░lš╣Ę■äšę╗¾w╗»ĮŌøQĘĮ░ĖīŻ╝ęĪŻÆ▀ę╗Æ▀┴ó╝┤ĻPūóĪŻ

ČÓŠSČ╚Ą─«aśI蹊┐║═Ęų╬÷Ż¼░č╬š╬┤üĒ░lš╣ÖCĢ■ĪŻÆ▀┤aĻPūóŻ¼½@╚ĪŪ░čžąąśIł¾ĖµĪŻ